Say Hello to the Internet of AI
Every so often, I would notice that our upstream bandwidth consumption was going up. Average upload usage is growing 21.7% year over year, more than twice the rate of downstream growth. The network is finally tilting toward something symmetrical, after thirty years of being optimized to deliver television to couches. Every new piece of data from OpenVault made me wonder how AI would change the consumer internet. And as an old networking nerd, what really occupied my mind was how AI would impact the network itself.
My assumption was that AI would accelerate this. Personal AI agents querying the cloud all day. Smart-home devices streaming sensor data. Wearables, cameras, robots, and eventually cars, every endpoint a continuous source of upload traffic. The next bandwidth hog wouldn’t be Netflix in reverse. It would be your house, talking constantly to a model (or models.)
A lot of this is still wishful thinking. I realized I was on the wrong track because I was looking in the wrong places. The real action is happening far away from the madding consumer crowds. All I had to do was start pulling some threads, calling some old friends, sitting down and mapping it all. And of course try and make sense of the $700 billion in spending on “data centers” by the Hyperscalers.

At MWC 2026 in Barcelona, Nokia’s CEO Justin Hotard said that AI generates roughly 77 exabytes per month today, makes up about 20% of total network traffic, drives 1.3 trillion sessions a year, and processes more than 100 trillion tokens daily. More than half already runs over mobile networks. Bell Labs (owned by Nokia) forecasts AI traffic specifically growing at a 23% compound annual growth rate through 2034, ending up around 30% of total wide-area network traffic.
Cisco’s CEO Chuck Robbins recently said that agents will engage continuously, keeping traffic levels permanently elevated rather than spiking and falling. The numbers Cisco offers are vendor-flavored, so it is hard to separate reality from hot air.
Dean Bubley of Disruptive Analysis argues that AI agents will not generate substantial traffic on access networks to homes or businesses. The traffic will move inside corporate networks and between data centers on backbone networks. Mike Dano at Ookla is skeptical of Cisco’s predictions of agents constantly engaging with users across the internet. Tom Nolle, another veteran, points out that enterprises need to host AI to create AI network impact. Just accessing it doesn’t move the needle on traffic.
William Webb has questioned the most aggressive industrial-AI projections, noting that factories rarely need millisecond-coupled coordination across geographies. Industrial AI will matter in China and other new manufacturing economies. Having invested in many industrial intelligence companies, I can tell you most of them like the press releases more than the actual actions.
The skepticism, however, cannot contradict the data on hyperscaler buildouts and the sheer amount of money going to work. As I started to dig in, what emerged was a completely new internet (or network of networks) optimized entirely for AI. I call it the Internet of AI.
Let me walk you through the layers of this internet of AI, and how it is actually being built, from the inside out. A lot of this will seem familiar, because we started this journey back in 2005 with the launch of Amazon’s S3 service. It has been a relentless march that has gone into mach speed in recent times.
The way I see it, there are four layers to the AI network cake.
- Inside the AI data center.
- Data Center Interconnect.
- Internets of AI.
- Planetary AI Network.
Inside the AI Data Center
Inside hyperscale data centers, AI workloads have inverted the basic traffic pattern that defined the internet for thirty years. The dominant flow is no longer user to servers (what industry people call north to south), but GPUs talking to each other inside the same building (east to west). Training a frontier model means tens of thousands of GPUs running in lockstep at speeds legacy data center fabrics were never designed to handle. AI clusters need up to five times more connectivity than traditional hyperscale topologies.
Having covered the internet itself from the earliest days, I can say the ever increasing network scale is as much a certainty as death and taxes. When I was writing about cloud, and the emergence of mobile first world, I saw an exponential scale up. The emergence of data-driven cloud and applications meant that scale got even bigger.
The AI transition is much bigger in scale, and happening at a much faster clip. Most of these patterns started in the cloud era. East-west traffic became dominant inside data centers years ago, when every byte written to S3 or DynamoDB started getting replicated to multiple zones, none of it touching the public internet.
Hyperscalers began building their own subsea cables more than a decade ago. What AI has done is dramatically scale and accelerate every one of these patterns, and tighten the latency requirements in ways the cloud workload never did. The shape may not have fundamentally changed yet. The stress on the underlying infrastructure has.
Training gets the headlines because of the dramatic numbers, but inference is the economic engine. Every dollar spent on training has to be monetized many times over by inference, or the math doesn’t work. In the long run, inference will drive most of the buildout. The networking implications of inference are not the same as training. Inference traffic looks more like classic web services in some ways.
Many concurrent users, each generating a small request and a slightly larger response. But agentic workflows complicate this, with multi-step reasoning chains where one model calls another, retrieval queries pulling context from vector stores, and long-running sessions that maintain state. The volume scales differently. The shape sits between web services and training.
Some context on the training side. GPU clusters used for AI training reached 200,000 to 300,000 GPUs in 2025, with xAI’s Colossus and Anthropic-Amazon’s Project Rainier among the largest. The 2026 forecast pushes single clusters toward one million GPUs, and the first gigawatt-scale training data centers are coming online now and through 2027. Microsoft has warned about a “networking wall,” noting that the explosive east-west traffic generated by large AI models is pushing data center networks to their physical limits.
There is a good reason why Meta moved to lock in a multi-year fiber supply agreement with Corning. Optical capacity, once treated as a commodity, has become a strategic input that has to be secured years in advance. There is a growing shortage of physical fiber. If you want to see how AI is lifting all boats, look at the recent performance of fiber infrastructure providers like Zayo and Lumen.
The deeper shift is happening at the level of network architecture itself. For more than two decades, the fat tree, a hierarchical Clos topology, has been the workhorse of every hyperscale data center on the planet. Both ideas have surprisingly old roots. The Clos network is named after Charles Clos, a Bell Labs engineer whose 1953 paper “A Study of Non-Blocking Switching Networks” described a way to connect any telephone caller to any free receiver using a three-stage design with input switches, middle switches, and output switches, with every input connecting to every middle and every middle connecting to every output. It made telephone exchanges economically practical.
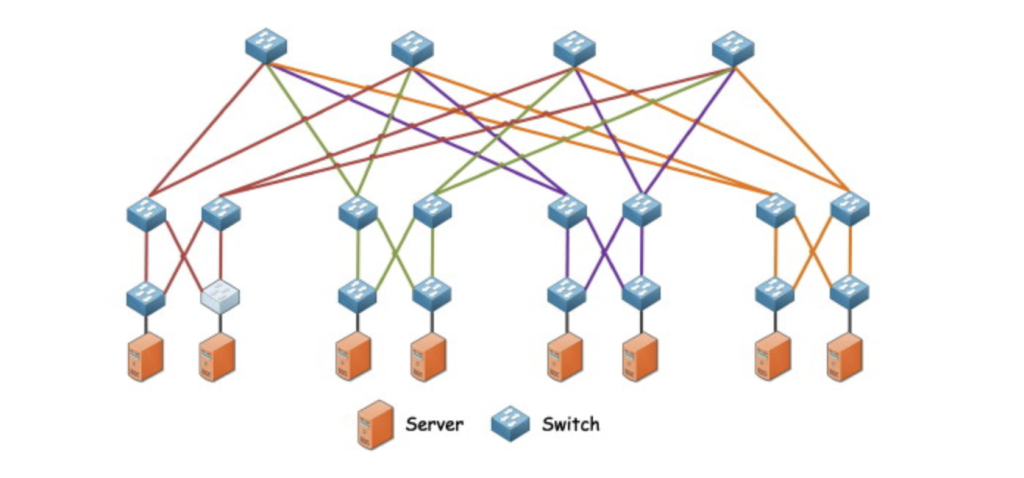
In 1985, Charles Leiserson at MIT extended the idea and came up with the concept of fat tree, for what was then known as parallel computing. The name describes what it looks like. A tree where the branches get thicker, carrying more bandwidth, as they climb toward the root. The thickening prevents the upper levels from becoming bottlenecks when many leaves are talking to many other leaves at once.
When the cloud era arrived in the 2000s, hyperscalers borrowed both ideas to design the data center networks that became the standard. Google, Meta, Microsoft, and AWS all built their first cloud-era data centers on this foundation.
The design assumed traffic between any two endpoints would be relatively predictable, and that capacity could be hierarchically aggregated through layers of spine and aggregation switches. AI workloads have broken that assumption.
The traffic that AI training generates does not look like cloud traffic. It moves in massive, sustained bursts between specific GPUs that need to stay in sync. The fat tree’s hierarchy was never designed for that. So either operators overbuild the fabric at huge cost, or they accept that AI jobs will choke on bottlenecks the design itself created.
Not surprisingly, every major hyperscaler is working hard to walk away from the old design thinking. Google in 2022, in its Jupiter Evolving paper described moving away from a Clos topology to a direct-connect fabric. By late 2024, Jupiter was running at 13 petabits per second of aggregate bandwidth. For Google this was a 30% capex reduction and 41% power reduction compared to the previous generation.
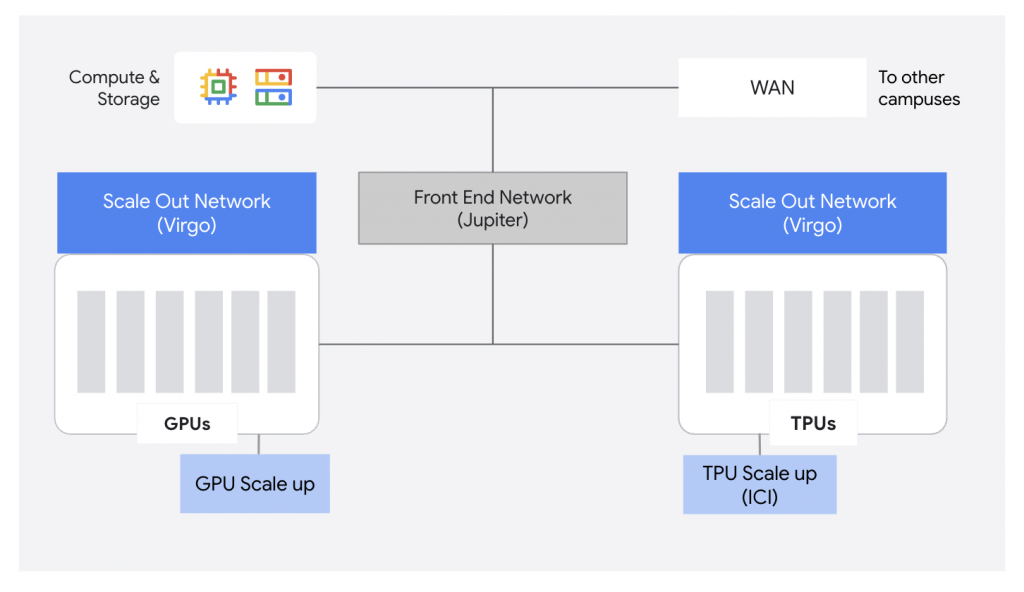
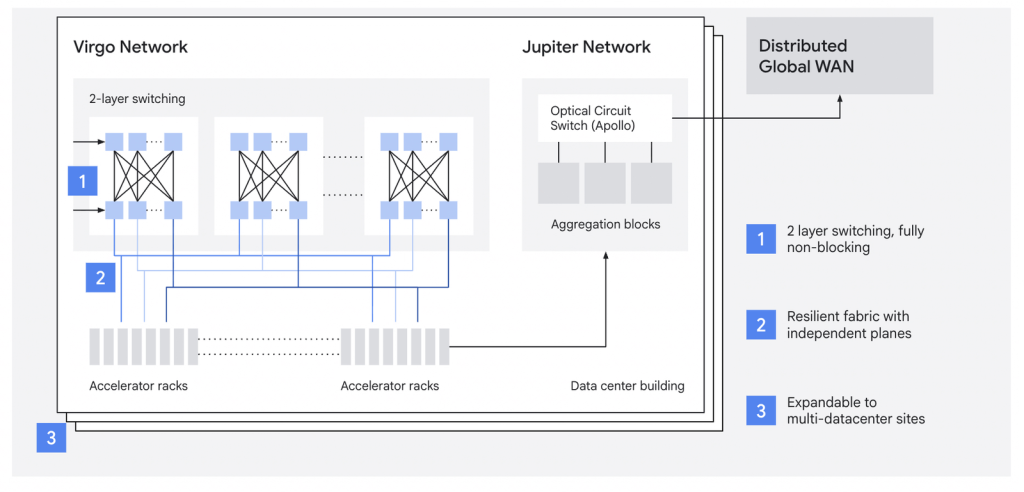
In April 2026, Google announced Virgo Network, a new megascale fabric designed specifically for AI. Google describes it as “a fundamental shift away from general-purpose network design towards a specialized flat, low-latency network architecture.” Virgo separates the AI accelerator-to-accelerator fabric (east-west, RDMA-based) from the Jupiter front-end network (north-south, for storage and general compute), and uses a flat two-layer topology.
Meta in its RDMA over Ethernet at Meta Scale paper (SIGCOMM 2024) has described splitting training clusters into separate front-end and back-end networks, with the back end engineered for GPU-to-GPU traffic. In October 2025, Meta described Disaggregated Scheduled Fabric, which scales this idea to interconnect thousands of GPUs across a data center region using deep-buffer switching specifically designed for distributed AI training.
AWS published its RNG paper in April 2026, describing the first production deployment of random graph topologies to replace fat trees, with a new routing protocol called Spraypoint and a passive optical device called a ShuffleBox. AWS reports 9% to 45% fewer switches than fat trees with equivalent performance, and significantly higher throughput on traffic patterns that dominate AI workloads.
In short, all four hyperscalers are giving the fat tree’s economic logic the thumbs down when it comes to AI workloads. Each has its own proprietary response. And you can bet your last penny that none of them is going to license their answer to the others. This is the same pattern that played out with custom silicon (TPUs, Trainium, Maia, MTIA), switches, and other gear. The hyperscalers see the workloads first, at scale, and they build the infrastructure to match. And they optimize, and optimize. The rest of the industry catches up later, if at all.
Still, there are dollars to be made. Network equipment makers are going whole hog into AI and creating new gear and new designs. In March 2026, Arista Networks introduced an optical pluggable standard called XPO, or eXtra-dense Pluggable Optics. It is designed specifically for AI data center fabrics. A single XPO module delivers 12.8 terabits per second of bandwidth with a roadmap to 25.6 terabits per second on 400-gigabit lanes. Each XPO module consumes more than 400 watts. According to Arista, a 400-megawatt AI data center would require 352 switch racks, a 75% reduction in network footprint from the current generation of gear. And that is before counting the corresponding reductions in electrical, cooling, and plumbing infrastructure.
As an aside, the fabric required to run a single hyperscale AI building is now larger than most enterprise data centers were a decade ago. Amazing, isn’t it.
It is not just optics (no pun intended). The switch market has revved up too. SONiC, the open-source networking operating system Microsoft developed for Azure, is on track to surpass $5 billion in data center switching revenue in 2026, driven by hyperscalers and neoclouds standardizing on Ethernet-based AI backends with 800G and 1.6T port speeds. Scale-up Ethernet, connecting GPUs and accelerators within a rack at speeds previously reserved for proprietary interconnects like Nvidia’s NVLink, is projected to drive a fifteen-fold increase in data center Ethernet bandwidth over the next five years. Here is the interesting part. Almost none of this east-west traffic ever leaves the building it originates in.
Data Center Interconnect
The next layer up is the data center interconnect, the metro and long-haul fiber that links one cluster to another. This is the first layer where AI traffic shows up as a visible bandwidth purchase.
Zayo’s 2025 Bandwidth Report, released in June, shows bandwidth purchased for data center connectivity grew 330% from 2020 to 2024, with total bandwidth purchases more than doubling to reach 42.4 terabits. In 2024 alone, ten buyers, predominantly hyperscalers and carriers, accounted for nearly 62% of all bandwidth purchases. Hyperscalers were responsible for 57% of all metro dark fiber installations between 2020 and 2024, and 41% of all bandwidth deals exceeding one terabit. The largest long-haul dark fiber deal in 2024 was an 864-fiber-count purchase by a single hyperscaler.
Metro dark fiber purchasing grew 268% from 2023 to 2024 alone, while long-haul dark fiber grew 52.6%. Zayo’s CEO Steve Smith said the company booked more than $1 billion in AI-related long-haul deals in 2024, with another $3 billion in the pipeline. The shape of these orders has changed. Average long-haul orders ranged from 8 to 12 fibers in the pre-AI era. Now hyperscalers are routinely ordering 12 to 48 fiber pairs per route, with some orders reaching 144 to 432 fibers. Looking forward, Zayo’s third-party research forecasts metro fiber demand to grow at roughly 20% per year and long-haul fiber at roughly 35% per year through 2029. Zayo estimates 190 million new fiber miles will be needed by 2030 to meet projected demand.
In April 2026, Zayo announced it had secured an anchor customer, described only as “a leading global AI infrastructure partner,” for 8,000 route miles of new builds and overbuilds, representing more than 15 million fiber miles. This is the largest single network investment in new build and overbuild miles in Zayo’s history. In January 2025, Zayo had announced plans to build 5,000 new route miles by 2030. In less than 18 months, that target has tripled to more than 15,000 route miles and approximately 20 million fiber miles. Zayo now expects AI-related bandwidth demand to grow two to six times by 2030.
Lumen, a competitor to Zayo, has closed approximately $13 billion in private connectivity fabric deals with hyperscalers, neoclouds, and AI companies, and plans to nearly triple its intercity fiber footprint to 47 million miles by 2028.
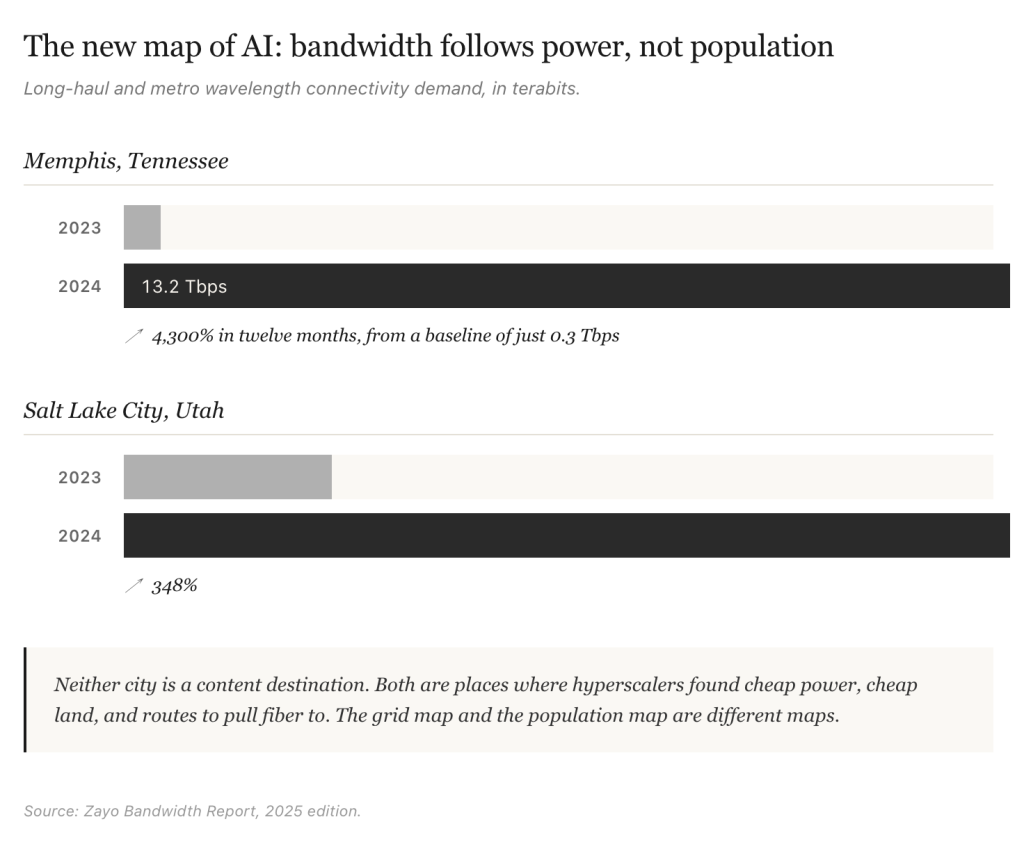
The geography of this growth is instructive. Memphis, Tennessee saw long-haul and metro wavelength connectivity demand grow from 0.3 terabits in 2023 to 13.2 terabits in 2024, a 4,300% increase in twelve months. Salt Lake City grew 348% over the same period. Neither city is a content destination. Both are places where hyperscalers found cheap power, cheap land, and routes to pull fiber to.
Compare this to cloud buildouts. They were closer to cheap hydro power in places like Oregon and Washington State, before expanding to other regions. Fiber was important during the cloud boom, but power is now the defining ingredient on network infrastructure.
The AI tsunami is lifting all boats. Once forgotten names are seeing salad days again. Ciena, which started making waves during Internet 1.0 before losing its cool, just raised its fiscal 2026 revenue guidance to between $5.9 billion and $6.3 billion, citing record orders from hyperscalers and a $7 billion backlog. Nokia bought Infinera for $2.3 billion in February 2025, and now its AI and cloud customer sales are up 49% in Q1 2026. Its addressable market for AI and cloud infrastructure is forecast to grow at a 27% compound annual rate through 2028, against 14% for broader network infrastructure.
Internets of AI
And then there is the long-haul fiber that connects regions and continents on land. This is the more interesting part because this is where you can truly start to see the private nature of the internet for AI.
Take Microsoft as an example. It now operates one of the largest backbone networks in the world, spanning more than 500,000 miles of fiber. According to its November 2025 disclosure, it added more than 120,000 new fiber miles across the United States in a single year, specifically to extend its dedicated AI wide area network (WAN), which connects its Fairwater AI superfactory campuses into a single system. Azure’s overall WAN capacity reached 18 petabits per second by late 2025, having tripled since the end of fiscal year 2024.
Microsoft is also investing heavily in Hollow Core Fiber, a technology that delivers data 47% faster and at 33% lower latency than conventional single-mode fiber. Microsoft acquired UK-based Lumenisity in December 2022 to bring this in-house, and is now scaling production through manufacturing partnerships with Corning and Heraeus. AWS is pursuing the same technology, currently using it across roughly ten data centers and working with three suppliers. The hyperscalers are no longer just buying fiber. They are reinventing it. This is what “vertical integration” can do.
Other hyperscalers are running similar buildouts, though specific mileage figures are less public. Google has always used its network to its advantage. Meta has been busy building its own networks as well. It is no surprise that a two-tier system has emerged.
Hyperscalers operate tightly controlled fiber supply chains with multi-year forward agreements. Enterprises depend on shared capacity with longer lead times and fewer customization options. They are now truly second-tier buyers, and not surprisingly many end up in the arms of hyperscalers.
To be fair, none of this is new. What is different is the sheer scale, and the dominance of the few companies controlling this fiber infrastructure. I have followed the story of the parallel internet for a very long time.
I first wrote about it in 2005, in a piece for Business 2.0 about what I called GoogleNet. In that story, I laid out an economic rationale for Google to build its own backbone instead of paying transit fees to middlemen like AboveNet. The thesis was simple. If you generate enough traffic, the math eventually flips. You stop paying for connectivity and start owning it.
Three years later, in February 2008, when Google announced its investment in the Unity transpacific cable, I wrote it up as confirmation of the thesis. Google has followed that math. The other hyperscalers eventually saw the logic of it as well. What looked like a quirky idea twenty years ago is now the standard operating model of the AI internet. Just the scale is completely different.

Planetary AI Network
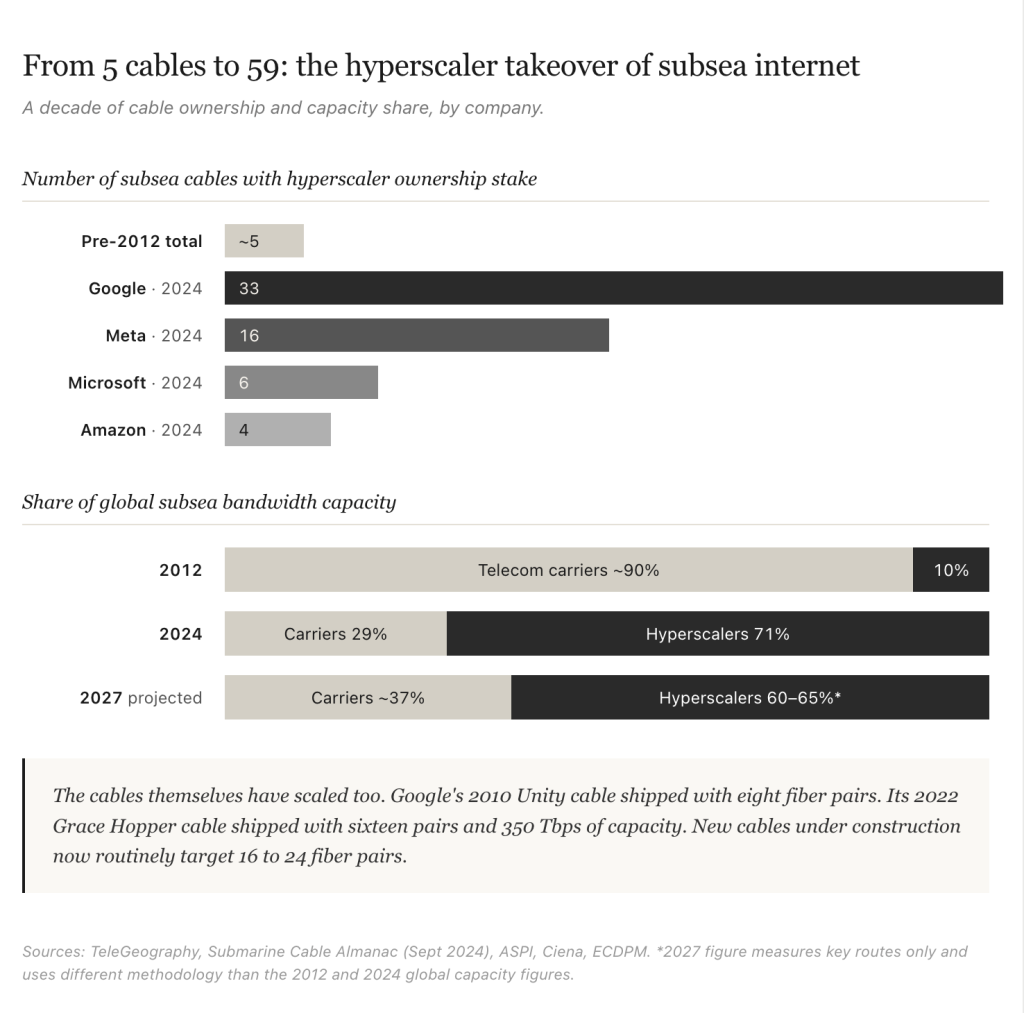
The most consequential layer is subsea. The cables that carry traffic between continents have always been a small, concentrated piece of internet infrastructure. As of early 2026, according to TeleGeography there are more than 600 active and planned cables, totaling over 1.5 million kilometers of subsea fiber in service. From when I started writing about them to now, what has changed is who owns them.
Before 2012, the four hyperscalers collectively accounted for less than 10% of total subsea cable usage. Google’s first investment came in February 2008, when it joined a six-member consortium to build Unity, a transpacific cable connecting Los Angeles and Chikura, Japan. The cable came online in 2010. As of 2024, the four together had stakes in 59 cable systems. Google leads with 33 cables (17 fully owned, 16 part-owned), Meta has 16, Microsoft 6, and Amazon 4. They now control roughly 71% of global subsea fibre capacity, around 80% of trans-Pacific bandwidth, and approximately 90% of transatlantic capacity. In 2012, traditional telecom carriers controlled roughly 80% of subsea capacity.

TeleGeography estimates that more than $14 billion in new cables will come into service from 2025 to 2027, compared with less than $5 billion invested between 2022 and 2024. Industry forecasts project hyperscalers controlling 60% to 65% of total transoceanic bandwidth capacity on key routes by 2027, up from roughly 30% in 2020.
While the dollar signs get the biggest attention, what has also changed is the cables themselves. Unity, which came online in 2010, had eight fiber pairs, which was state of the art at the time. Google’s Grace Hopper, which came online in 2022, had sixteen fiber pairs and 350 terabits per second of capacity. New cables under construction now routinely target 16 to 24 fiber pairs.
Hyperscalers, including Google and Meta, are now building cables for their own internal needs first, retaining capacity, and releasing only excess to the wholesale market. With AI workloads and all the new kind of traffic emerging, none of this should come as a surprise.
The Power Question
Behind all of this is a single binding constraint.
Power.
Power and bandwidth are now coupled like never before. What started in the early cloud days has metastasized into something much larger. It is reshaping the geography of the network.
The geography of AI is shifting toward wherever cheap and reliable power exists, and the network is being redesigned around those nodes. Bandwidth follows power. Power does not follow bandwidth.
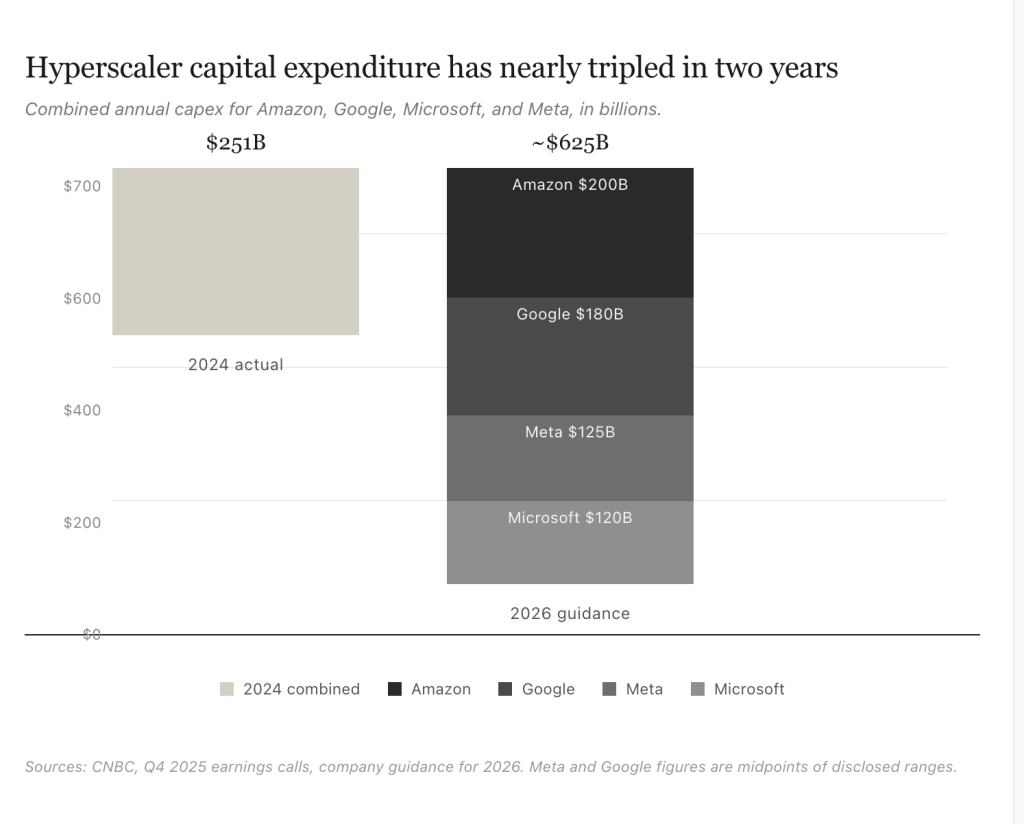
Hyperscaler capital expenditure for 2026 is forecast to exceed $600 billion, with some estimates closer to $700 billion. McKinsey projects global demand for data center capacity could nearly triple by 2030, with about 70% of that demand coming from AI workloads. Both training and inference are driving the buildout, and inference is expected to become the dominant workload by 2030. Power, not bandwidth, is the limiting factor. AI-driven data centers are creating sites with what one industry executive has described as “small-city loads,” with highly volatile profiles driven by training and inference workloads. Since the grid cannot keep up, on-site generation and bridging power solutions are becoming popular.
The new AI network is developing its own geography, very different from the original Internet, the broadband Internet and the cloud Internet. The grid map and the population map are different maps. AI infrastructure is being aligned with the former rather than the latter.
The New AI Network
The pitch is a new layer of edge inference, sitting between the hyperscaler core and the consumer access network. Phone companies are desperately clawing their way into what they and others think is the next phase of the buildout.
At NVIDIA’s GTC 2026 conference in March, several large operators announced what NVIDIA calls AI grids. These grids are distributed AI infrastructure built on telco network footprints, with sites interconnected to bring inference closer to users.
When I read that Akamai is putting NVIDIA Blackwell-edition GPUs into more than 4,400 edge locations, I chuckled. So now, inference is the new content, and Akamai wants to be the Inference Delivery Network. Others like Charter Communications’ Spectrum (1,000 edge data centers within ten milliseconds of 500 million devices) and T-Mobile (integrating GPUs directly into radio access network sites) are showing their hand, and their desperation.
They have to. I mean, what are they going to do with current infrastructure? Telcos and distributed cloud providers collectively run about 100,000 distributed network data centers worldwide. NVIDIA estimates these locations could host more than 100 gigawatts of new AI capacity over time, more than the combined power footprint of every hyperscale data center currently in service. Of course it does, as long as they keep paying Jensen Huang the baksheesh.
I am skeptical of all this edge inference story. It is the same old wine with a new label. A version of the edge inference story has been told before, repeatedly, and has not played out the way it was predicted. Edge computing and cloudlets were supposed to be the next big thing a decade ago, driven by similar low-latency arguments. They mostly didn’t materialize.
The value of pooled, manageable, non-stranded resources at a hyperscaler is hard to beat. The vendors most loudly promoting edge inference, NVIDIA, Akamai, the carriers, all have direct economic interest in the story working out. There are real use cases for edge inference, particularly for the physical AI workloads I describe below, but I would not bet the farm on this layer the way I would on the hyperscaler core, the data center interconnects, or the subsea backbone.
Where the edge layer might genuinely matter is physical AI. Robotic systems, including autonomous vehicles, delivery drones, industrial robots, and augmented reality field workers, cannot tolerate the latency variability of consumer broadband. They require very high uptime with deterministic latency budgets. This forces some inference toward the edge, where it can run within tight latency windows. If physical AI deploys at the scale forecasters are predicting, the edge layer becomes worth building. If it deploys more slowly, the edge layer remains a niche.
The carriers, meanwhile, are being demoted. The 5G dream of telcos selling cloud services on top of their networks has effectively died. What’s left is carriers serving as transport for hyperscaler traffic. To put it in human terms, they are the phone network on which FaceTime and WhatsApp run. Sure, they get their monthly charges, but the real value is with Apple and Meta. Their one possible escape route is converting their distributed central-office and cell-site footprint into edge inference real estate, the AI grid model NVIDIA has been pitching. Given the historical track record of edge computing predictions, I would not bet on this conversion materializing at scale. The desperation economics of telecommunication makes carriers do and say crazy things.
Choo Choo AI
The right historical analogy for what is happening with AI is not Web 2.0 or the cloud. It is the railroads of the nineteenth century. Railroad operators understood the freight cars were not where value lived. The value was in owning the rails and everything around them, including the land. Owning the rails meant controlling routes, latency, geography, redundancy, and the cost structure of every customer who depended on the network.
Track gauge, terminal access, trunk-line ownership, and route concessions were the levers of competitive position. Rail barons built private networks that operated alongside, and sometimes parallel to, public common-carrier infrastructure. The Interstate Commerce Act of 1887 was a response to that imbalance. The rails of the AI era are hyperscaler-owned fiber, optical interconnect, and subsea cable. The handful of companies building them are doing so on a capital scale comparable to the mid-cycle American railroads of the 1870s and 1880s. The strategic logic is the same.
Owning the rails means owning the toll booth. Every train that runs has to pay you, whether you operate it or not. That is what the hyperscalers now own at the infrastructure layer of AI.
Which raises a question worth asking directly. Who ends up with the real long-term moat at this layer, Nvidia or the hyperscalers?
The answer is as obvious as the day itself. Just recently both Anthropic and OpenAI decided to give up big chunks of themselves to Amazon. Anthropic gave even more to Google. They may carry the hype of being AI cool kids, but in the end they have to pay the toll to the hyperscalers. Sure, it is all funny money at present, but it is still a toll.
After listening to Jensen Huang on a recent podcast, I came away even less convinced that he is in charge over the long term, despite Nvidia’s supply chain lock and software ecosystem. The company has effectively become the toll booth on the chip layer, the way Intel was for general-purpose compute for thirty years.
What Nvidia doesn’t have is the scale of the hyperscalers. Unless Huang decides to use his immense market capitalization to become a hyperscaler himself, and start competing with his own customers, the ones who buy his big honking GPUs. Just as Intel didn’t try to upend the PC makers, neither will Jensen. Instead, he will try to figure out how to sell more chips to the Chinese, the Indians, and anyone else who has cash to burn.
Like the railroads, hyperscalers have customers, workloads, and hence the monetization. They control the layer above the chips, and they are increasingly designing their own silicon to escape the Nvidia tax. Google has TPUs. Amazon has Trainium and Inferentia. Microsoft has Maia. Meta has MTIA. This is exactly what AWS and Azure did with general-purpose cloud, and it is why those two became beasts.
We still have understood that owning all the networks, and building their own fabrics, they can easily switch workloads, such as training for zones across the planet, and do it much cheaper, when it is cheaper to do so. The network is their advantage.
My bet is the hyperscalers win in the long run. The historical pattern is clear. Whoever owns the workload, the customer relationship, and the monetization eventually wins. It is way easier to route around any single supplier. Even someone as dominant as Nvidia.
The vertical integration of hyperscalers will eventually have a compounding effect. The hyperscalers’ moat compounds because every new workload they win deepens their data, customer, and operations advantage. Like AWS and Azure with cloud, AI will help the hyperscalers own the application-layer rents in the long run.
Now back to OpenVault and the consumer broadband data that started this piece. Sooner or later, billions of humans and trillions of bots are going to have an impact on the network. I know this as instinctively as I did when I first pointed out Netflix was the first real killer app of broadband. It is just a matter of time when AI will be the new Netflix!
(First published on) May 4, 2026. San Francisco.
Dear Om,
In my early salad days around 2008-10, i prepared a talk on the four horsemen of the apocalypse cloud, mobile, big data, and social saying these forces were shaping the future with a sea of complexity and changing business models. Later added AI and software defined anything and discarded IOT. The times they are changing said early seer bob dylan. Thanks as always for making us think deeply on these forces and their implications.