What Do PayPal and Cisco Have in Common?
Updated with comment from Cisco: Question: What do PayPal and Cisco have in common? Answer: Both suffered widespread outages over the past 24 hours, proving yet again that despite all the progress that’s been made, Internet infrastructure remains prone to human error and other random problems.
Earlier this morning I heard from some of my friends in the infrastructure business who told me that Cisco.com had gone down at around midnight.
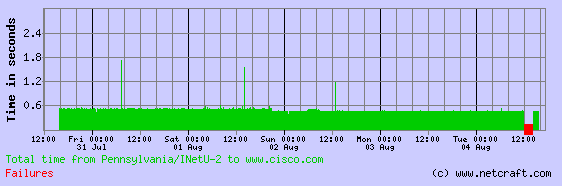 |
We are still awaiting a response from Cisco about the current outage, and what might have brought upon this outage. PayPal, by comparison, was a tad more generous with its details. It blamed the failure of network equipment.
About two years ago, Cisco had a similar outage. “The issue occurred during preventative maintenance of one of our data centers when a human error caused an electrical overload on the systems,” the company had explained on its blog. “This caused Cisco.com and other applications to go down.” Update: A Cisco spokesperson emailed me the following statement as well:
I can confirm that www.cisco.com experienced an outage of just over 2 hours this morning/afternoon. This was an inadvertent result of a change made during regular maintenance – a change that has since been reversed returning www.cisco.com to normal service. We thank our customers and partners for their patience and apologize for any inconvenience they may have experienced.
I wonder what the human error really was? What about load-balancing and those resiliency measures the folks at Cisco like to talk about? I mean, what’s the point of having a blog (unless you want to just publish news releases) if you can’t be elaborate and transparent as to what really happened?
PS: Looks like I referred to an older post incorrectly. The error is regretted. No excuses – just a straight-up mistake.
The link you provide to the Cisco outage has a date stamp of Aug 9, 2007. Is this the link you wanted to reference?
Tom
thanks for pointing that out. I totally botched it. Sorry about the error. Fixed to reflect my error.
Hmm. Earnings day is today. Probably not a good idea to schedule maintenance the night before.
Further, this is a black eye – Cisco of all companies should have had redundancy so that an alternate data center should have kicked in using any number of products it itself manufactures. Own dog food and insert other metaphors here…
I wonder which vendor’s network equipment experienced a failure at PayPal. That must have been one heck of a hardware failure affecting multiple devices, with the assumption that they would have implemented a highly redundant/fault-tolerant infrastructure.